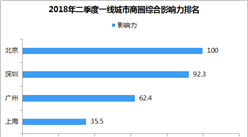
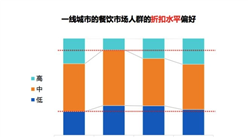
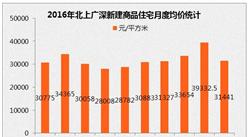
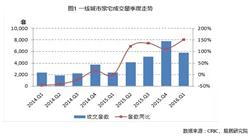
来解释一下算法。这一次新一酱采用的空间分析方法是聚类和异常值分析(Anselin Local Moran's I)。首先新一酱沿用并微调了上次的模型,为不同类型的兴趣点赋予了不同的权重:
餐饮×0.1
高级酒店×0.15
经济型酒店×0.08
银行×0.1
奢侈品×0.25
零售×0.1
地铁站点×0.2
公交站点×0.02
根据这个权重,新一酱进一步用核密度算法计算了每500米×500米栅格的商业资源指数。
接下来,新一酱设定了4个条件,从这近5千万个栅格中,选出了一批格子。这4个条件包括:栅格本身商业密度高,周边栅格商业密度高,周边栅格商业密度差异小,以及与其越近的栅格商业密度越高。
新一酱认为,满足这些条件的栅格组合形成的区域就可以被称作商业区了。对于每个独立的商业区而言,区内所有栅格的商业资源指数总和则可以用来表示这个商圈完整的商业实力。
你可以从下面几个有代表性的例子来更好地理解这套算法。
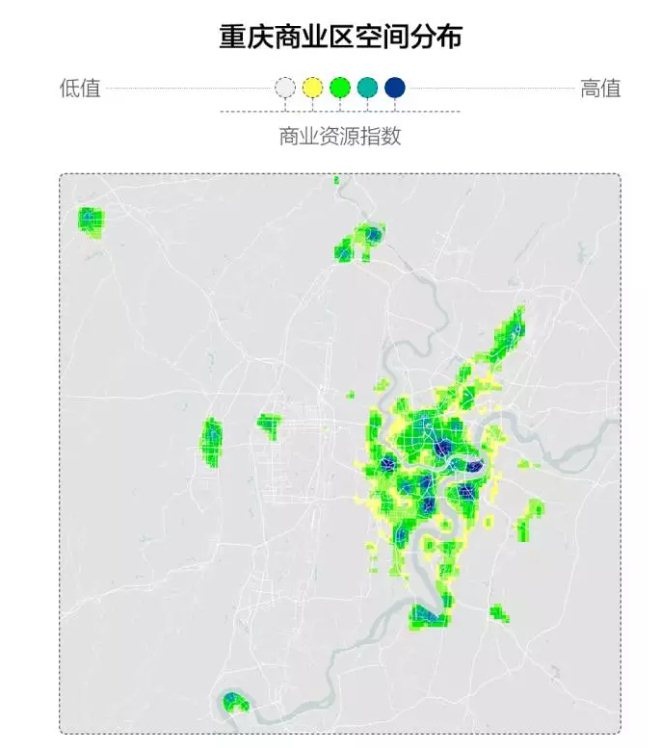
在上面重庆的商业区空间分布图中,蓝色表示商业资源的中心聚集区,而黄色表示商业资源的周边蔓延区。
可以明显看出,重庆是一个典型的单商业区、多商业中心的城市。在上一次的研究中,新一酱已经识别出了观音桥、三峡广场、解放碑、杨家坪和南坪步行街这5个传统的商业中心。而在这一版的计算中,石桥铺、大坪和九宫庙等新兴商业中心也凸显了出来——尤其是大坪的时代天街,其商业资源指数已几乎可以与五大传统商业中心相抗衡。

 如发现本站文章存在版权问题,烦请联系editor@askci.com我们将及时沟通与处理。
如发现本站文章存在版权问题,烦请联系editor@askci.com我们将及时沟通与处理。


 中商产业研究院:《2020年中国加氢站行业市场前景及投资研究报告》发布
中商产业研究院:《2020年中国加氢站行业市场前景及投资研究报告》发布
 锤子科技CEO罗永浩跨界电商直播 一文看懂我国电商直播发展如何?
锤子科技CEO罗永浩跨界电商直播 一文看懂我国电商直播发展如何?
 中商产业研究院:《2020年中国MCN行业市场前景及投资研究报告》发布
中商产业研究院:《2020年中国MCN行业市场前景及投资研究报告》发布
 2020年1-2月全国汽油产量为2044万吨 同比下降13.9%
2020年1-2月全国发电量同比下降8.2%
2020年1-2月全国集成电路产量为296.3亿块 同比增长8.5%
2020年受疫情影响较大的行业分析系列之三——旅游行业篇(图)
2020年1-2月全国光缆产量统计数据分析
2020年1-2月全国发动机产量同比下降38.8%(图)
2020年1-2月全国十种有色金属产量为935.4万吨 同比增长2.2%
2020年1-2月全国汽油产量为2044万吨 同比下降13.9%
2020年1-2月全国发电量同比下降8.2%
2020年1-2月全国集成电路产量为296.3亿块 同比增长8.5%
2020年受疫情影响较大的行业分析系列之三——旅游行业篇(图)
2020年1-2月全国光缆产量统计数据分析
2020年1-2月全国发动机产量同比下降38.8%(图)
2020年1-2月全国十种有色金属产量为935.4万吨 同比增长2.2%